
Connection Pool이 없을 때의 문제
웹 개발을 하다보면 보통 애플리케이션에서 DB를 사용한다.

하지만 매번 DB가 필요한 요청마다 매번 위의 과정을 거쳐 DB에 연결을 하게 되면 비용이 상당히 많이 든다.
- DB 연결을 생성하는 과정에서 네트워크 연결, 인증 등의 과정이 필요하다.
- 각 연결은 메모리와 네트워크 리소스를 사용하기 때문에 많은 연결을 만들면 서버 리소스가 빠르게 소모된다.
- 데이터베이스 서버도 각 연결을 관리해야 해서 부하가 증가할 수 있다.
- 연결 생성에 시간이 소요되어 전체 응답 시간이 늘어나고 애플리케이션 성능이 저하된다.
- DB와의 연결을 위해 생성한 java.sql.Connection 등 연결 객체의 GC 처리가 필요한데, GC 작업이 빈번할 수록 성능 저하가 발생할 가능성이 있다.
Connection Pool이란
Connection Pool은 위의 문제를 해결하기 위한 방법으로, 미리 DB에 연결한 객체를 생성해놓고 재사용하여 비용을 줄일 수 있다.
사용 가능한 연결 객체가 없고 최대 크기에 도달하지 않았다면 새 연결을 만든다.
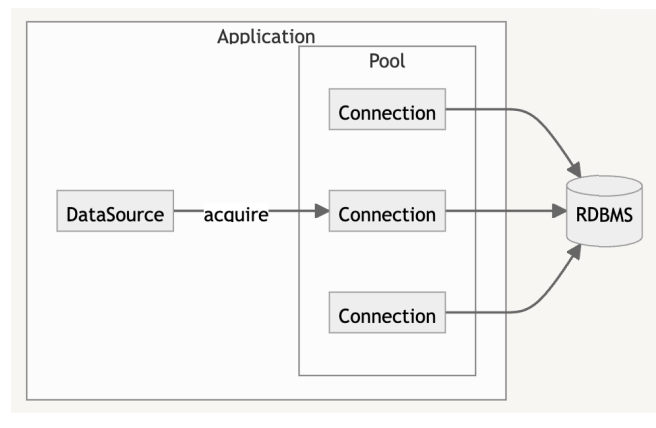
실제 Connection Pool을 사용했을 때와 아닐 때를 비교해보면 약 6배가량 차이가 나는 것을 알 수 있다.
(HikariCP를 사용했다. 해당 코드)

HikariCP란?
HikariCP는 JDBC Connection Pool을 지원하는 라이브러리 중 하나로, 가볍고 빠른 것이 특징이다.
또한 Spring Boot 2.0 부터 HikariCP를 동시성과 성능을 이유로 기본 데이터 소스로 채택하고 있다.
HikariCP 깃헙에 가보면 속도에 대한 자랑이 굉장히 많은데, 다른 라이브러리에 비해 매우 빠른 이유는
- ConcurrentBag을 사용해서 최적화
- 코드 전반에 걸쳐 불필요한 동기화를 최소화
- 락의 사용을 극도로 제한하여 스레드 간 대기 시간 감소
ConcurrentBag이 뭔가 해서 Claude 선생님께 여쭤보니...
ConcurrentBag은 여러 스레드가 각자 필요한 자원을 빠르게 확보하고 반납할 수 있도록 설계된 컬렉션입니다.
ConcurrentBag은 마치 여러 개의 작은 가방(각 스레드용)과 하나의 큰 가방(공유)이 있는 것처럼 작동하는데,
스레드가 자원을 요청할 때, 우선적으로 자신의 "작은 가방"에 접근하는 덕분에 이미 할당된 자원을 재사용할 가능성이 높아지고, 캐시와 같은 효과를 내어 성능을 개선합니다. 또한, 공유되는 "큰 가방"에서 자원을 가져오거나 반환하는 경우에도 잠금(lock) 횟수를 줄이기 위해 설계된 구조를 사용하여 동시성 비용을 최소화합니다.
HikariCP 설정
HikariCP 레포에 가보면 초기화 과정 중 설정 예시를 들고 있는데, 주요 설정의 의미와 어떻게 설정하면 좋을지 알아보자
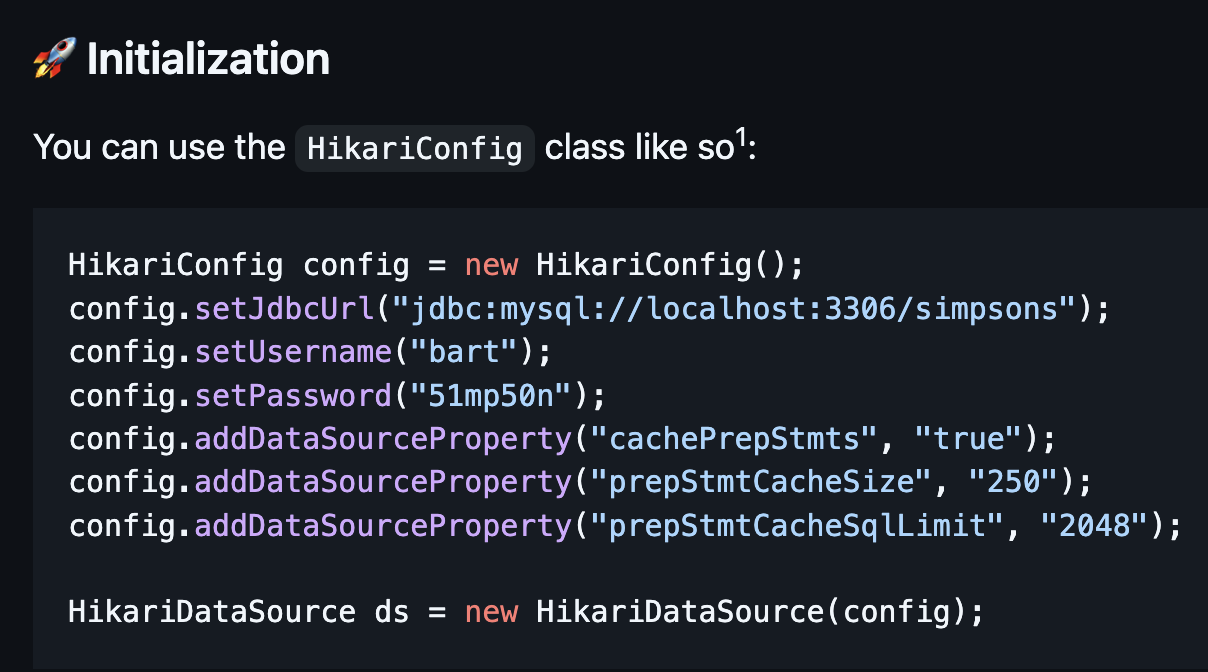
기본 DB 설정 뿐만 아니라 쿼리문 날릴 때 생성되는 PreparedStatement를 각 쿼리별로 캐싱해두는 설정을 할 수 있다.
- cachePrepStmts
- PreparedStatement 캐싱을 활성화합니다.
- PreparedStatement를 재사용하여 SQL 파싱과 실행 계획 생성 단계를 건너뛰게 됩니다.
- 반복적으로 실행되는 쿼리의 성능을 크게 향상시키고 데이터베이스 서버의 부하를 줄입니다.
- 메모리 사용량이 증가할 수 있으므로, 적절한 캐시 크기 설정이 중요합니다.
- PreparedStatement 캐싱을 활성화합니다.
- prepStmtCacheSize
- 커넥션 당 캐시할 PreparedStatement의 수를 지정
- 250개의 서로 다른 PreparedStatement를 캐시할 수 있습니다.
- 자주 사용되는 쿼리들이 이 캐시에 저장되어 빠르게 재사용됩니다.
- 애플리케이션에서 사용하는 고유한 SQL 문의 수를 고려하여 설정합니다.
- 너무 작으면 캐시 효과가 줄고, 너무 크면 메모리 사용량이 증가합니다.
- 커넥션 당 캐시할 PreparedStatement의 수를 지정
- prepStmtCacheSqlLimit
- 캐시할 SQL 문의 최대 길이를 바이트 단위로 지정합니다.
- 2048바이트보다 긴 SQL 문은 캐시되지 않습니다.
- 매우 긴 SQL 문으로 인한 메모리 낭비를 방지합니다.
- 애플리케이션에서 사용하는 SQL 문의 평균 길이를 고려하여 설정합니다.
- 너무 작으면 복잡한 쿼리가 캐시되지 않고, 너무 크면 메모리 사용량이 증가할 수 있습니다.
- 캐시할 SQL 문의 최대 길이를 바이트 단위로 지정합니다.
참고해서 현재 애플리케이션의 상태에 맞는 캐시할 쿼리 갯수를 파악하고 쿼리문의 크기도 조정하면 좋을듯하다.
우리꺼는 몇 개 나가는지 궁금해지네,,
'우아한테크코스 6기 > 4단계' 카테고리의 다른 글
| 다양한 캐시 전략에 대해 알아보자 (2) | 2024.10.27 |
|---|---|
| Grafana, Prometheus로 TPS 측정 및 시각화하기 (0) | 2024.10.14 |
| 고가용성과 SPOF (0) | 2024.10.01 |
| JPA에서 Full Text Index 사용하기 (+ 테스트 시 주의점) (0) | 2024.10.01 |
| API 성능 개선하기 2탄 (feat. 검색 전문 인덱스 적용하기) (1) | 2024.09.28 |